[3일차] 데이터 기초2
[데이터 문제정의 및 수집]
▶문제 정의 필수 고려사항
- 문제의 목표 정의
- 문제 범위 결정
- 문제 결과에 대한 성공 기준
- 문제 해결에 필요한 시간 및 비용
▶데이터 정의 필수 고려사항
- 문제에 관련된 데이터에 필요한 속성
- 문제 해결에 필요한 데이터 수집 방법
- 데이터 처리 및 분석을 위한 Tool
- 최종 결과물의 형태와 전달 대상
▶문제 정의 사례

[데이터 수집]


- DBMS 수집 : DB에 직접 연결해 데이터 수집
- FTP 수집 : 대용량 파일을 수집하기 위해 클라이언트 서버와 연결 (get / put 명령 기능)
[Open API]

[데이터 전처리, 파이프라인]
데이터 전처리 : 정확하고 신뢰 할 수 있는 데이터 마이닝 결과를 추출하기 위하여 데이터의 분석 및 처리에 적합한 형식으로 데이터를 조작하는 과정
데이터 품질 저해 요소
- Noise : 잡음
- Artifact : 왜곡 (ex. 카메라에 묻은 얼룩)
- Outlier : 이상치
- Missing Values : 결측치
- Inconsistent values : 모순, 불일치
- Duplicate : 중복
데이터 전처리 단계
- 데이터 정제 : 비어있는 데이터나 잡음, 모순된 데이터 등을 정합성이 맞도록 교정하는 작업
- 데이터 통합 : 여러 개의 데이터베이스, 데이터 집합 또는 파일을 통합하는 작업
- 데이터 변환 : 데이터를 정규화, 이산화 또는 집계를 통해 변환하는 작업
- 데이터 축소 : 샘플링, 차원축소, 특징 선택 및 추출을 통해 데이터 크기를 줄이는 작업
[데이터 전처리의 단계 세부 설명(축소)]

[데이터 파이프라인]
- 다양한 원본에서 데이터를 수집하고, 비즈니스 규칙에 따라 데이터를 변환하고, 대상 데이터 저장소로 로드하는데 사용되는 데이터 파이프라인
람다 아키텍처 : 배치와 실시간 분석을 지원하는 빅데이터 아키텍처

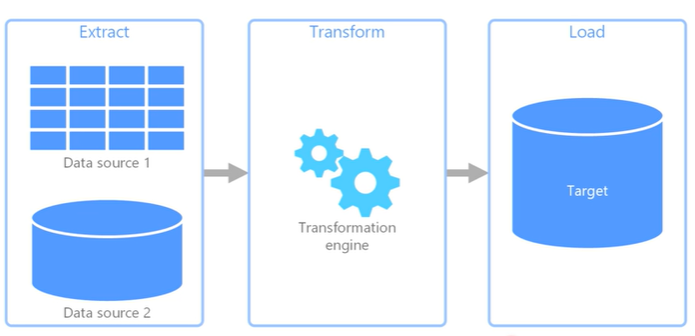
[데이터 ETL (추출, 변환 및 로드) ]
Extract -> Transform -> Load
- 다양한 원본에서 데이터를 수집하고, 비즈니스 규칙에 따라 데이터를 변환하고, 대상 데이터 저장소로 로드하는데 사용되는 데이터 파이프라인
[데이터 ELT (추출, 로드, 변환) ]
Extract -> Load <-> Transform
- ETL 과 다르게 별도 변환 엔진을 사용하는 대신, 대상 데이터 저장소의 처리 기능을 상ㅇ하여 데이터를 변환하는 데이터 파이프라인

[데이터 파이프라인 on Cloud ]
- 서버리스 함수를 통해 작업을 트리거하고, 오브젝트 스토리지의 데이터가 저장되고 ETL 작업을 수행하여 목적 서비스에 전달
[데이터 파이프라인 Streaming 모델]
- IoT 디바이스에서 생성되는 실시간 데이터의 처리를 수행하는 데이터 파이프라인
[데이터 저장]
하둡(Hadoop)
- 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 분산 소프트웨어 플랫폼
- 분산처리 시스템인 구글 파일 시스템을 대체할 수 있는 하둡 분산 파일 시스템(HDFS, Hadoop Distributed File System)과 맵리듀스를 구현한것

[하둡 에코시스템]

[HDFS (Hadoop File System) ]


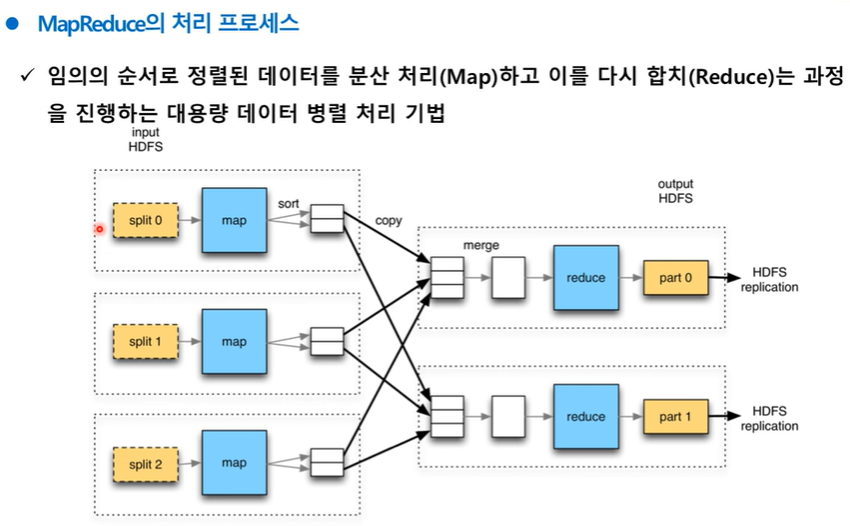
[맵리듀스 (MapReduce) ]


[Spark]



[데이터 저장소]
네트워크 스토리지 : 네트워크를 통해서 클라이언트들이 접근하여 데이터를 저장, 복사 등 디스크 작업을 할 수 있는 저장장치
- NAS 네트워크 스토리지 (Network Attached Storage)
- SAN 네트워크 스토리지 (Storage Area Network)

SDS (Software Defined Storage)

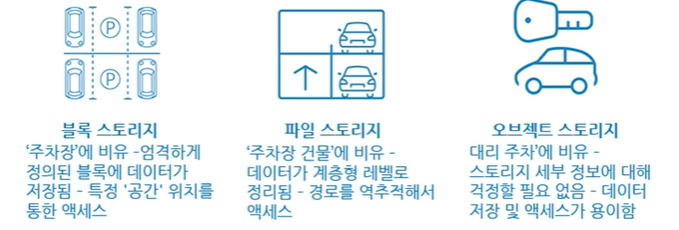
[스토리지 서비스 유형]
블록 스토리지 / 파일 스토리지 / 오브젝트 스토리지
[데이터 웨어하우스 & 데이터 레이크]
DATA WAREHOUSE(DW)
- 기업의 대단위 데이터를 사용자 관점에서 주제별로 통합하여 축적하여 별도의 장소에 저장해놓은 자료

[DW 다차원모델링]
- Star Schema / Snowflake Schema
[OLAP]
- On-Line Analytical Processing
- 다차원적 정보를 관련자들이 공유해 빠르게 분석하는 과정

[데이터레이크]
- 대용량의 정형 및 비정형 데이터를 원시형태 그대로 저장하고 손쉽게 접근할 수 있게 하는 대규모 리포지토리
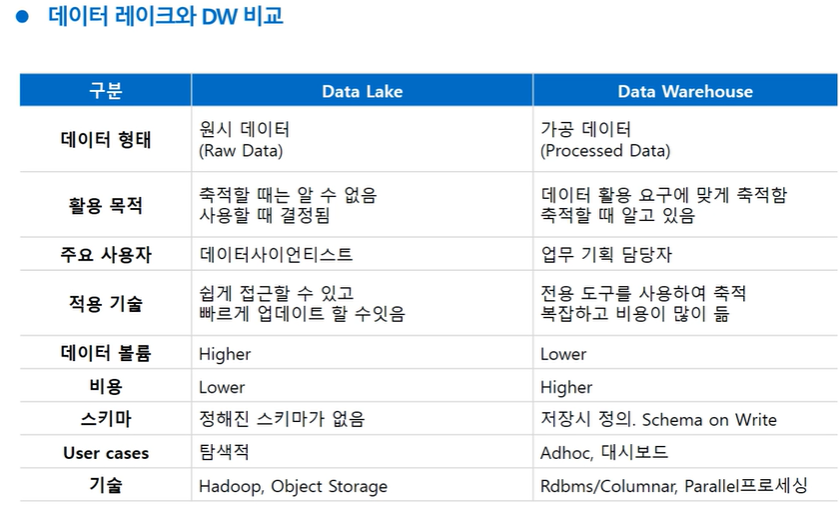
[데이터 레이크와 DW 비교]
[Data Lake House의 개념]
- 데이터레이크와 데이터웨어하우스의 최고의 요소를 결합한 새로운 패러다임

[데이터 분석의 이해 1]
데이터분석방법론
- KDD(Knowledge Discovery in Database)
- CRISP-DM(Cross Industry Standard Process for Data Mining) : 가장 일반적인 방법
- SEMMA(Sampling Explore Modify Modeling Assesment)
데이터 분석과제 발굴
- 하향식 접근 방법
- 상향식 접근 방법
데이터 분석 방법 유형

[데이터 분석의 이해2]
모집단과 표본
확률추출
확률분포


[통계적 가설 검정]

[회귀분석]


[분산분석]

[주성분분석]
- PCA (Principal Component Analysys)
- 다루기 힘든 고차원의 신호를 낮은 차원으로 줄여 다루기 쉽게 하는 통계적 방법
[정형 데이터분석]

[비정형 데이터 분석]
텍스트 마이닝

SNA (소셜 네트워크 분석)

[데이터기반행정의 현재와 미래 1]