[이론 1] 문자열/리스트 활용
- append()
- remove()
- sort()
- insert()
외에 활용 방법
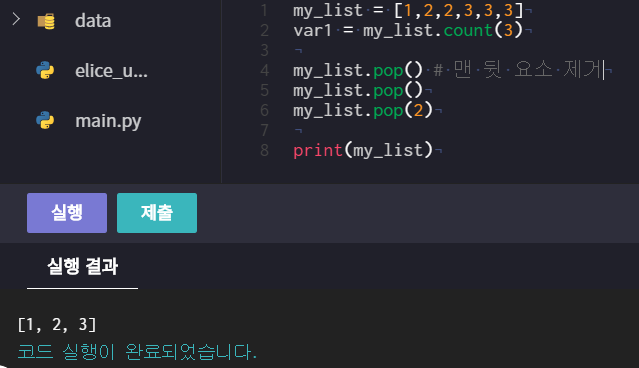
# list.pop(i)
- 인덱스 i의 원소를 제거 후 그 원소를 반환 (괄호를 비울 시 마지막 원소)
ex) my_list = [1,2,3,4,5] => my_list.pop(0) # 1 / my_list.pop( ) # 5
# seq.count(d)
- 시퀀스 내부의 자료 d의 개수를 반환
ex) my_seq = [2,2,2,4,4] => my_seq.count(2) # 3
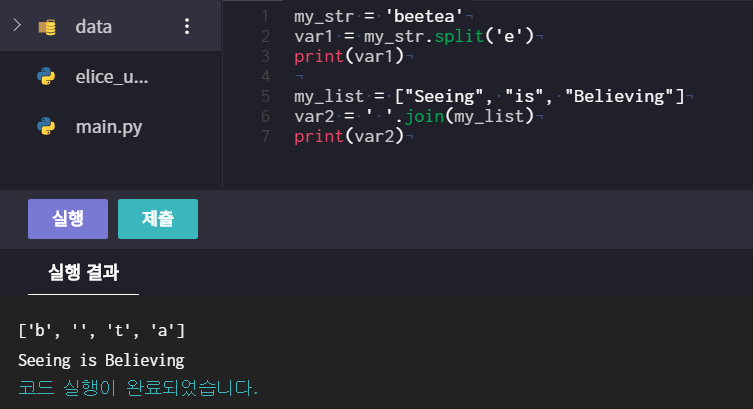
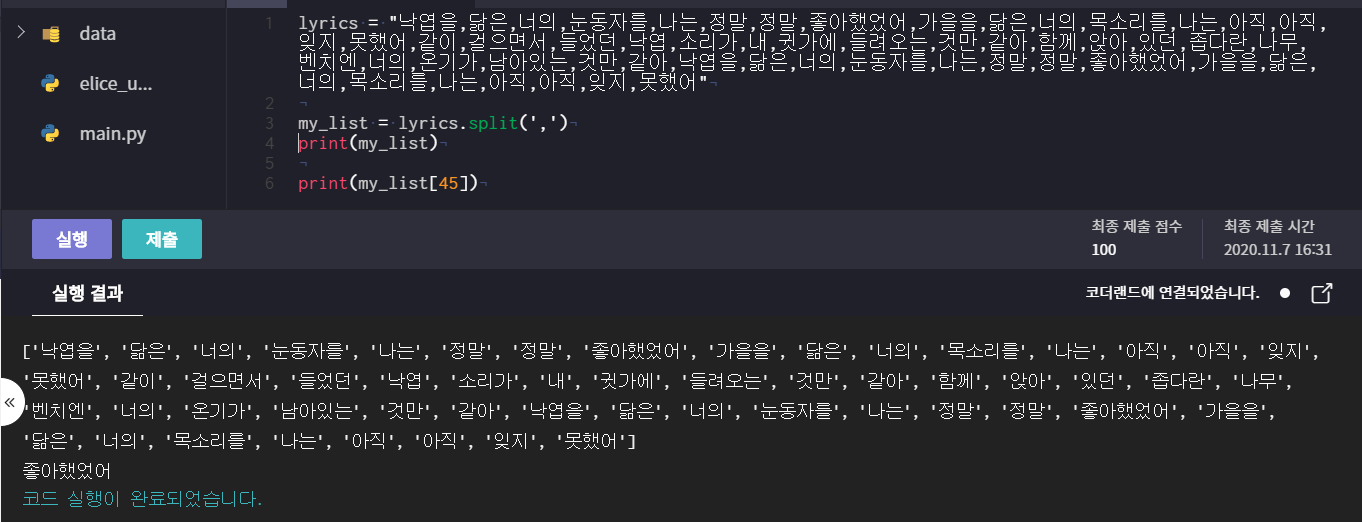
# str.split(c)
- c를 기준으로 문자열을 쪼개서 리스트로 반환 (괄호를 비울 시 공백)
ex) element = 'Na,Mg,Al,Si' => element.split(,) # ['Na', 'Mg', 'Al', 'Si']
** 문자열을 리스트로
# str.join(list)
- str을 기준으로 리스트를 합쳐서 문자열을 반환 (괄호를 비울 시 공백)
ex) my_list = ['a', 'p', 'p', 'l', 'e'] => ''.join(my_list) # apple
friend = ['Pat', 'Mat'] => '&'.join(friend) #Pat&Mat
** 리스트를 문자열로
[이론 2] 튜플
- 여러 자료를 담는 자료형이 필요하다면? -> 대부분 리스트를 이용 but 값이 바뀔 위험이 있다.
- 리스트안의 원소들을 추가, 제거, 변경할 수 있으므로
ex) my_list = ['l',' 'i', 's', 't']
my_list[1] = 'a'
print(my_list) # ['l',' 'a', 's', 't']
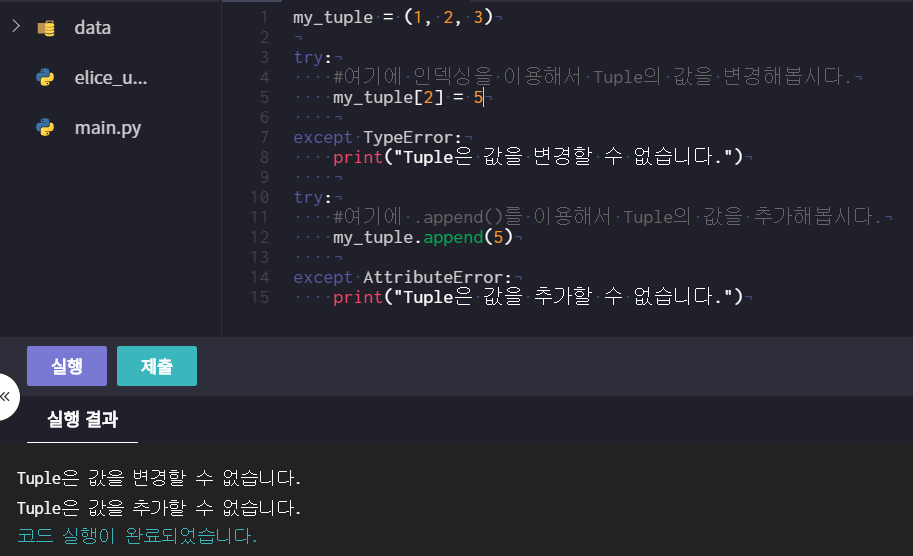
# 튜플(Tuple)의 필요성
- 값을 바꿀 수 없으면서도 여러 자료를 담기 위함!
# 튜플
- 여러 자료를 함꼐 담을 수 있는 자료형
- ( ) 소괄호로 묶어서 표현
# 튜플의 특징
- 튜플은 시퀀스 자료형으로 index를 이용한 인덱싱, 슬라이싱이 가능
- in 연산자로 Tuple 안에 원소 확인
- len() 함수로 Tuple의 길이 확인
- + 연산자로 Tuple과 Tuple을 연결
- * 연산자로 Tuple을 반복
- 여기까진 튜플과 리스트의 특징이 같으나
★ Tuple은 자료가 추가, 삭제, 변경되지 않는다. 한 번 만들어지면 고정 됨!
[이론 2] 딕셔너리(Dictionary)
- 짝꿍이 있는 자료형!
- { } 중괄호로 묶어서 표현
- {key : value} 형태 : key를 알면 value를 알 수 있음
- key는 열쇠처럼 자료를 꺼낼 수 있는 도구
# Dictionary[key]
- 인덱싱처럼 key를 이용해 Dictionary에서 자료 꺼내기
- 인덱싱처럼 key를 이용해 Dictionary에 자료 추가하기
ex) person = {'name':'Michael', 'age':10}
person['hometown'] = 'Seoul' => 변수를 할당하는 것 처럼 넣어준다
-> dict -> key ->value
# del
- del 함수로 Dictionary의 원소 삭제
ex) person = {'name':'Michael', 'age':10}
del person['age']
-> dict -> key
# Dictionary의 특징
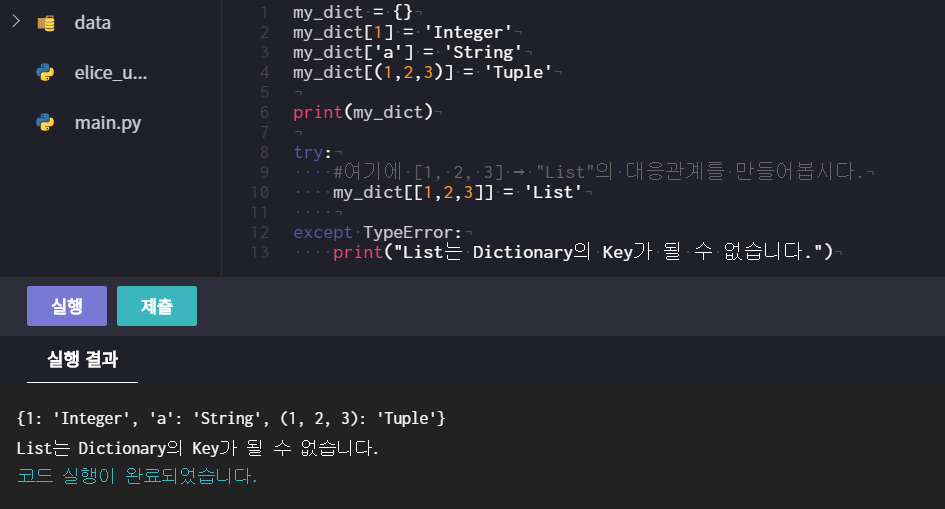
- Key는 변할 수 없는 자료형이어함!
- 그러므로 list는 key가 될 수 없고 , tuple은 key가 될 수 있다
ex) data = { [1,2,3] : 'Alphabel'} # Error
data = { (1,2,3) : 'Number'} # OK
- 또한, 2개 이상의 동일한 Key가 있어선 안 됨

★
[총 정리]
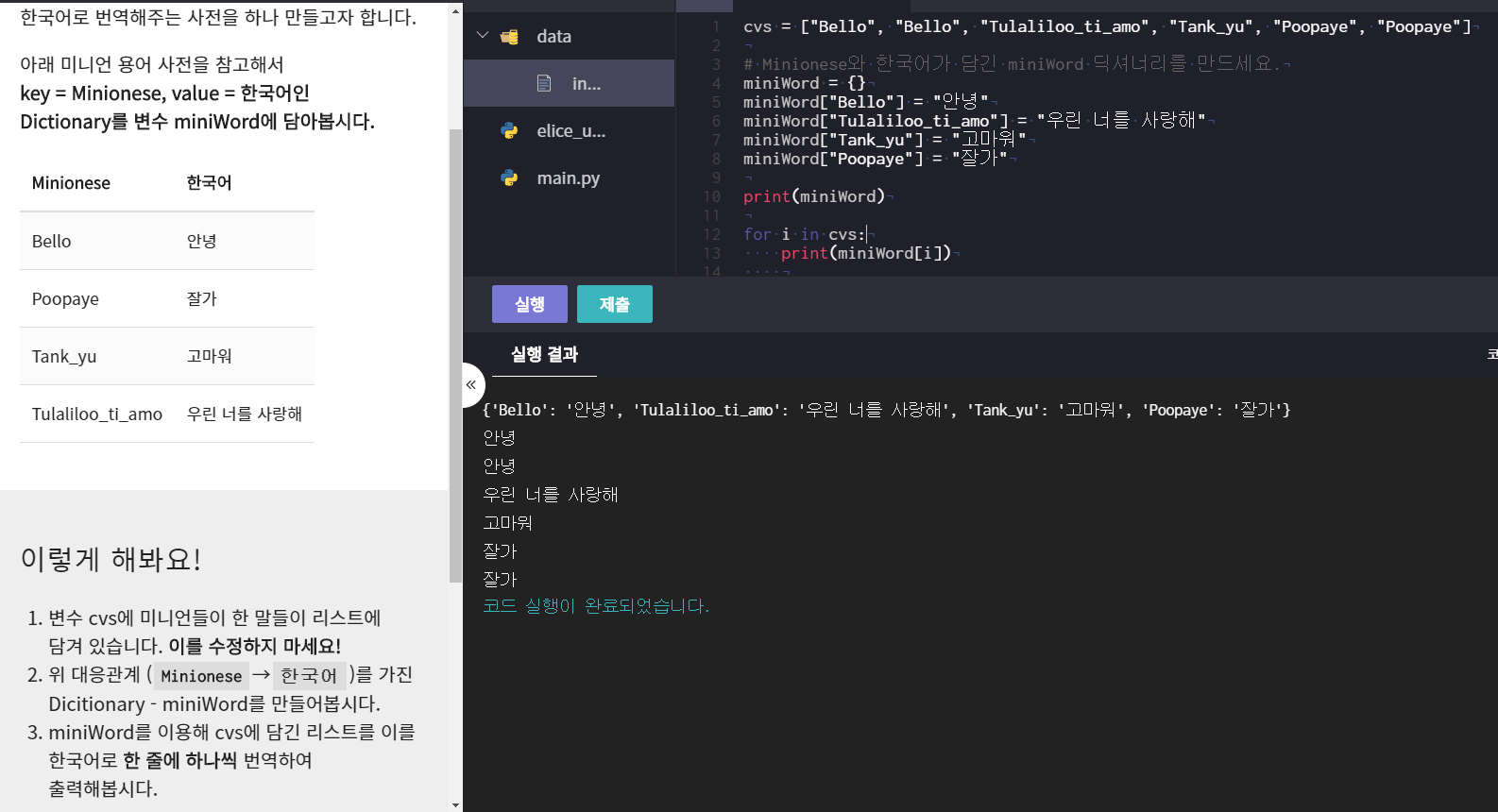
1. 시퀀스 활용하기
Point I
list.pop(i) : 인덱스 i의 원소를 제거 후 반환
lst = [1, 2, 3, 4, 5] box = lst.pop(0) # lst에서 1을 제거 후 반환, 이 경우에는 변수 box에 대입 print(lst) # [2, 3, 4, 5] print(box) # 1
Point II
seq.count(d) : 시퀀스 내부의 자료 d의 개수를 반환
carrot = "Hi Rabbit!"
print(carrot.count("i")) ## 실행 결과
## 2
Point III
str.split(c) : 문자열 c를 기준으로 문자열 str을 쪼개서 리스트를 반환
ours = "나,너,우리"
print(ours.split(","))
# ['나', '너', '우리']
Point IV
str.join(list) : str을 기준으로 list를 합쳐서 문자열을 반환
coffee = ['a', 'm', 'e', 'r', 'i', 'c', 'a', 'n', 'o']
print("".join(coffee)) # 빈 문자열("")을 기준으로 합치기
# americano
2. Tuple(튜플)
Point I
여러 자료를 담을 수 있으면서, 변하지 않는 자료형
Point II
() - 소괄호로 묶어 표현
tup = (1, 2, 3, 4, 5)
Point III
원소가 하나라면 반드시 원소 뒤에 ,을 적어주어야함
tup_one = (1,)
Point IV
시퀀스 자료형의 성질을 지님
cute = ('c', 'a', 't')
print(cute[1]) #인덱싱
#'a'
print(cute[1:]) #슬라이싱
#('a', 't')
print('e' in cute) #in연산자
#False
print(len(cute)) #len연산자
#3
print(cute + ('e', 'g', 'o', 'r', 'y')) #연결연산
#('c', 'a', 't', 'e', 'g', 'o', 'r', 'y')
print(cute * 3) #반복연산
#('c', 'a', 't', 'c', 'a', 't', 'c', 'a', 't')
Point V
자료를 추가, 삭제, 변경할 수 없다!
hero = ("ant", "man") hero.append("wasp") #Error
hero.remove("man") #Error
hero[0] = "iron" #Error
3. Dictionary(사전형)
Point I
짝꿍(Key → Value)이 있는 자료형
Point II
{} - 중괄호로 묶어서 표현
hp = {"gildong" : "010-1234-5678"}
Point III
key를 알면 value를 알 수 있다.
dic = {"apple":"사과", "banana":"바나나"}
print(dic["apple"]) # 사과
Point IV
del 키워드로 Dictionary의 원소 삭제
리스트의 원소를 삭제하는 것도 가능!
dic = {"apple":"사과", "banana":"바나나"}
del dic["apple"]
print(dic) # {"banana":"바나나"}
Point V
Key는 변할 수 없는 자료형이여야 한다
dic = {[1, 3, 5]:"odd"} #Error
dic = {(2, 4, 6):"even"}
'자습' 카테고리의 다른 글
| [/*elice*/ 도레미 파이썬 Vol.2] 06. 함수와 메서드-인공지능 활용을 위한 파이썬 기초 (0) | 2020.11.07 |
|---|---|
| [/*elice*/] 04. 반복문-인공지능 활용을 위한 파이썬 기초 (0) | 2020.11.07 |
| [/*elice*/] 03. 리스트-인공지능 활용을 위한 파이썬 기초 (0) | 2020.11.07 |
| [/*elice*/] 02. 조건문-인공지능 활용을 위한 파이썬 기초 (0) | 2020.11.06 |
| [/*elice*/] 01. Python 개론 및 Python 기초 자료형 /인공지능 활용을 위한 파이썬 기초 (0) | 2020.11.06 |




댓글