6. 빅데이터 탐색
- 빅데이터 탐색 개요
- 빅데이터 탐색에 활용되는 기술
- 탐색 파일럿 실행 1단계 - 탐색 아키텍처
- 탐색 파일럿 실행 2단계 - 탐색 환경 구성
- 탐색 파일럿 실행 3단계 - 탐색 기능 구현
- 탐색 파일럿 실행 4단계 - 탐색 기능 테스트
빅데이터 탐색 개요
- 탐색 영역은 적재된 데이터를 가공하고 이해하는 단계
- 데이터 이해 => 데이터들의 패턴, 관계, 트렌드 찾기 => 탐색적 분석(EDA:Exploratory Data Analysis)
- 탐색 과정은 분석에 들어가기에 앞서 빅데이터의 품질과 인사이트를 확보하는 매우 중요한 단계
- 비정형 데이터를 정교한 후처리 작업(필터링, 클린징, 통합, 분리 등) => 정형화 데이터
- 탐색 결과는 곧 바로 분석 마트를 위한 기초데이터로 활용
- 이런 일련의 처리/탐색, 분석/응용 과정 => 빅데이터 웨어하우스
데이터 웨어하우스(DW: Data Warehouse)
- 운영 시스템과 연계하여 의사 결정 지원에 효과적으로 사용 될 수 있도록 다양한 운영 시스템으로부터 추출, 변환, 통합되고 요약된 읽기 전용 데이터베이스
데이터 마트(Data Mart)
- 전사적으로 구축된 데이터웨어하우스로부터 특정 주제, 부서 중심으로 구축된 소규모 단일 주제의 DW
빅데이터 탐색에 활용할 기술
- 하둡 초창기에는 맵리듀스(MapReduce) 사용, 복잡도가 높은 프로그래밍(Java) 기법 필요
하이브(Hive) SQL on Hadoop
- http://hive.apache.org
- 하둡 기반 적재된 데이터 탐색/가공 도구
- SQL과 매우 유사한 방식으로 하둡 데이터에 접근
- CLI : 하이브 쿼리 입력 및 실행
- JDBC/ODBC Driver: 다양한 DB와 하이브 쿼리 연결 드라이버
- Query Engine: 하이브 QL => MapReduce
- MetaStore: 하이브에서 사용하는 테이블의 스키마 정보를 저장 및 관리
- CLI/웹콘솔 => QL 작성 => QE의 SQL 파서 => MapReduce 프로그램 => 분산 실행
- QL로 스마트카 데이터 조회, 결합, 분리, 변환, 정제 => 스마트카 DW => 스마트카 DM
- 적재 Data => 하이브 External => 정제 => Managed 영역 => 각 영역별 Mart
- 유사 프로젝트 : Pig
스파크(Spark)
- http://spark.apache.org
- 하이브는 QL로 접근성은 높였지만 맵리듀스 코어 그대로 사용하여 성능이 떨어짐(반복적 작업시)
- 고성능 인메모리 분석 => 하이브, 피그는 디스크 I/O
- 스파크SQL, 스파크스트리밍, 머신러닝등 작업시 빠른 성능
- 파이썬, 자바, 스칼라, SQL등의 클라이언트 라이브러리 제공
- 스파크엔진은 대규모 분산 노드에서 최적의 성능
- HDFS, HBase, 카산드라등의 데이터 소스 연결 이용
- 스파크쉘에서 스파크-SQL API를 이용해 ''스마트카 마스터 '' 조회 및 정제 작업
우지(Oozie)
- http://oozie.apache.org
- 하이브나 스파크로 처리/탐색/분석하는 과정은 복잡한 선후행 관계를 맺고 반복 진행됨
- 반복적이고 복잡한 후처리 잡에 대한 시작,처리,분기,종료의 Action 워크플로우 정의
- Oozie Workflow: 주요 액션에 대한 작업규칙과 플로우 정의
- Oozie Client: 워크플로우를 Server에 전송하고 관리하기 위한 환경
- Oozie Server: 워크플로우 정보가 잡(Job)으로 등록되어 잡의 실행,중지,모니터링 관리
- Control 노드 : 워크플로의 흐름을 제어하기 위한 Start, End, Decision 노드등 기능 제공
- Action 노드: 잡의 실제 수행 태스크를 정의하는 노드 , 하이브,피그, 맵리듀스등 액션으로 구성
- 하이브QL의 External => Managed => Mart 과정의 약속된 스케줄링을 우지 워크플로우로 구성
휴(Hue)
- http://gethue.com
- 다양한 하둡 에코시스템의 기능들을 웹 UI로 통합 제공
- Job Designer: 우지의 워크플로 및 Coordinator 를 웹 UI에서 디자인
- Job Browser: 등록한 잡의 리스트 및 진행 상황과 결과등 조회
- Hive Editor: 하이브 QL을 웹 UI에서 작성
- Pig Editor: Pig Script을 웹 UI에서 작성
- HDFS Browser: 하둡의 파일시스템을 웹 UI에서 탐색 관리
- HBase Browser: HBase의 HTable을 웹 UI에서 탐색 관리
- 웹에디터를 이용해 '스마트카 상태 데이터', '스마트카 운전자 운행 데이터' 탐색 수행
- '스마트카 마스터 데이터'와 '스마트 차량 물품 구매이력' 임포트 작업 수행
- 휴의 Job Designer를 이용해 Oozie 의 워크플로 5개의 주제 영역별 작성 및 실행
탐색 파일럿 실행 1단계 - 탐색 아키텍처
탐색 요구사항
요구사항 1
- 차량의 다양한 장치로부터 발생하는 로그 파일을 수집해서 기능별 상태를 점검
요구사항 2
- 운전자의 운행 정보가 담긴 로그를 실시간으로 수집해서 주행 패턴을 분석
요구사항 구체화 및 분석
적재된 데이터는 하이브의 데이터 웨어하우스로 관리
- 하이브의 데이터 웨어하우스기능 이용
- 초기 HDFS 적재영역(External) => Managed => Mart 단계적 구성
데이터 마트 구축에 필요한 데이터를 추가 구성
- HDFS 명령어로 '스마트카 마스터 데이터'와 '스마트 차량 물품 구매이력' External에 추가 적재
하이브의 데이터 웨어하우스의 이력성 데이터들을 일자별로 관리
- 데이터 웨어하우스의 External 영역은 작업 처리일 기준으로 파티션 구성
- Managed 영역은 데이터 생성일 기준으로 파티션닝
분석 마트가 만들어지는 일련의 과정들을 워크플로우로 만들어 관리
- Oozie를 사용해 하이브 QL을 Job Designer에 등록 워크플로를 만들고 스케줄러에 등록 및 관리
분리 탐색한 데이터는 외부 애플리케이션이 빠르게 접근하고 조회할 수 있어야 한다
- 휴의 Job Designer를 이용해 Oozie 의 워크플로 5개의 주제 영역별 작성 및 실행
최종 마트로 만들어질 데이터셋들은 주제 영역별로 구성
- 스마트카의 상태 모니터링 정보
- 스마트카의 운전자의 운행 기록 정보
- 이상 운전 패턴 스마트카 정보
- 운전자의 차량용품 구매 이력 정보
- 긴급 점검이 필요한 스마트카 정보
탐색 아키텍처 P 226 참고
휴 Hive Editor로 External 조회
- Hive Editor를 이요해 SQL과 유사한 방식으로 조회
- HBase에 적재된 데이터도 Hive HBase 핸들러 이용 RDBMS 처럼 데이터 탐색
External과 HBase 적재된 데이터 작업일자 기준 후처리 작업
- Managed 영역에 스마트카 로그 생성일자 기준으로 2차 적재
- External 영역 => 하이브 QL => Managed 영역
Managed에 만들어진 데이터는 탐색적 분석에 활용
- 데이터가 구조화, 정형화 데이터로 전환된 상태
- 의사결정에 필요한 다양한 데이터 추출 단계
- 우지의 워크플로를 이용 해 프로세스화 및 자동화
실시가 탐색 파일럿 실행 2단계 - 탐색 환경 구성
저사양 파일럿 환경 서비스 중지
- CM 정지: 플럼, 카프카
- 스톰 정지: service storm-ui stop, service storm-supervisor stop, service storm-numbus stop
- 레디스 정지: service redis_6379 stop
- 수집, 적재 시뮬레이터 등도 정지
Hive 설치
- CM > 클러스트1 > 서비스 추가 > Hive 선택 > 계속
- 종속성 집합 > HBase 선택 > G, HMS, HS2 Server02 선택 > 계속
- 하이브 MetaStore DB 설정(기본) > 테스트연결 > 계속
- 변경 내용 검토(기본) > 계속
Oozie 설치
- CM > 클러스트1 > 서비스 추가 > Oozie 선택 > 계속
- 종속성 집합 > HBase 선택 > OS Server02 선택 > 계속
- Oozie External DB 설정(기본) > 테스트연결 > 계속
- 변경 내용 검토(기본) > 계속
Hue 설치
- CM > 클러스트1 > 서비스 추가 > Hue 선택 > 계속
- HS Server02 선택 > 계속
- 변경 내용 검토(기본) > 계속
Hue 설치 후 구성 변경
- CM > Hue > 구성 > 검색 > 시간대 > Asia/Seoul > 변경 내용 저장
- CM > Hue > 구성 > 검색 > HBase Thrift 서버 > HBase Thrift Server (server01) 확인
- Hue 이전 서비스 재시작
Spark 설치
- CM > 클러스트1 > 서비스 추가 > Spark 선택 > 계속
- HS, G Server02 선택 > 계속
Spark 설치 후 YARN에서 작동 하도록 구성
- CM > YARN > 재시작
- CM > 작업 > 클라이언트 구성 배포
- CM > 스파크 > History Server 웹 UI
탐색 파일럿 실행 3단계 - 휴를 이용한 데이터 탐색
- CM > Hue > 웹 UI > admin / admin
- http://server02.hadoop.com:8888/

휴의 빠른 시작 마법사 구성
1단계: 구성 확인
-
구성 파일 위치 /var/run/cloudera-scm-agent/process/214-hue-HUE_SERVER
- 모두 정상입니다. 구성 검사를 통과했습니다.
-
/ 권한 오류시
- su - hdfs
- hdfs dfs -stat "%u %g" /
- hdfs dfs -chown hdfs:supergroup /
- su
2단계: 애플리케이션 및 예제 설치
3단계: 사용자 설정
4단계: 건너띄기 선택 후 완료 버튼 => 내문서 페이지
HDFS에 적재된 데이터 확인
상단MENU > HDFS 브라우저(파일 브라우저)
- /user/admin => /pilot-pjt/collect/car-batch-log/wrk_data=20160101
- 파일 내용 확인도 가능
HBase에 적재된 데이터 확인
상단MENU > Data Browser > HBase > Hbase 브라우저
- 내용 확인
- 저사양은 확인 후 서비스 중지
하이브(Hive)를 이용한 External 데이터 탐색
SmartCar_Status_Info 테이블 생성
- External 데이터: /pilot-pjt/collect/car-batch-log/wrk_data=20160101
- Query Editors => Hive => \bigdata-master\CH06\HiveQL\2nd
- 그림-6.49.hql (Drag and Drop) => Hive External 테이블 생성
- 스키마가 없는 데이터 파일을 하이브 스키마로 정의 메타스토어에 등록
- QL로 해당 파일 접근 가능
- 그림-6.50.hql (Drag and Drop) => 작업일자 기준 파티션 정보 생성(wrk_data=20160101 날짜로 생성)
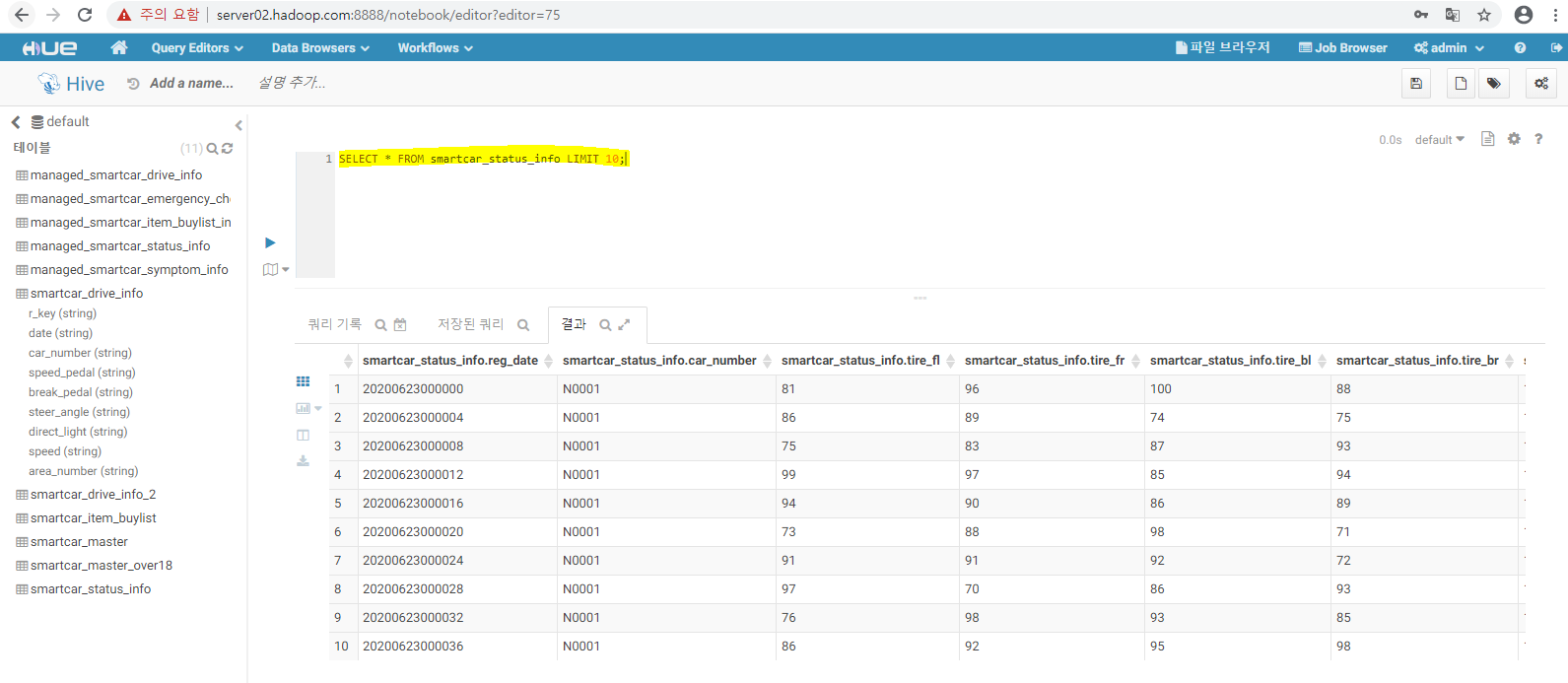
- 쿼리실행 : 그림-6.51.hql (Drag and Drop) => limit 절사용 빠른 조회
- 쿼리오류 시 파일럿 프로젝트는 default 사용 확인
- 쿼리기록 : 기존 사용했던 쿼리 확인 가능
- 쿼리 연습
|
select car_number, avg(battery) as battery_avg |
- Job Browser메뉴를 통해 변환 실행된 맵리듀스 정보로 확인 가능
SmartCar_Driver_Info 테이블 생성
- Query Editors => Hive => 그림-6.58.hql
- HBase의 DriverCarInfo 칼럼 패밀리와 매핑해 생성
| select * from SmartCar_Drive_Info limit 10; |
데이터셋 추가
- 스마트카 마스터 데이터 : Ch06/CarMaster.txt
- 스마트카 차량용품 구매 이력 데이터: Ch06/CarItemBuyList_201606.txt
- 휴 파일 브라우저 업로드 기능 이용 => 하이브 External Table 로 정의
CarMaster.txt
- /pilot-pjt/collect/car-master 생성 후 CarMaster.txt 업로드
- 차량번호|성별|나이|결혼여부|지역|직업|차량용량|차량연식|차량모델
CarItemBuyList_201606.txt
- /pilot-pjt/collect/buy-list 생성 후 CarItemBuyList_201606.txt 업로드
- 차량번호|구매상품코드|만족도(105)|구매월
권한 오류시 : admin 권한 생성
you are a Hue admin but not a HDFS superuser, "hdfs" or part of HDFS supergroup, "supergroup"
- cat /etc/group |grep supergroup
- useradd admin -g supergroup
- useradd admin -g supergroup
- sudo -u hdfs hadoop fs -chown admin /pilot-pjt/collect
Hive SmartCar_Master 테이블 생성
- QE > Hive > 그림-6.65.hql
| select * from smartcar_master; |
Hive SmartCar_Item_BuyList 테이블 생성
- QE > Hive > 그림-6.67.hql
| select * from smartcar_item_buylist limit 10; |
Spark를 이용한 추가 데이터 탐색
- 스마트카 마스터 데이터를 Spark-SQL 사용 탐색
- Spark Shell 사용
- Server02 ssh 접속
- su - hdfs
- spark-shell
- scala> var smartcar_master_df = sqlContext.sql("select * from smartcar_master where age >= 18")
- scala > smartcar_master_df.show()
- scala > smartcar_master_df.saveAsTable("SmartCar_Master_Over18")
- QE > smartcar_master_over18 생성 확인
| select * from smartcar_master_over18 where age > 30 and sex = '남' |
참고: spark 가 hive 보다 3배 정도 빠름
탐색 파일럿 실행 4단계 - 데이터탐색 기능 구현 및 테스트
- 데이터 탐색 자동화와 마트 구성
- External 적재 데이터 => Managed 통합 시키는 우지 워크플로우 잡
- Managed 영역과 Mart 영역을 하나의 절차로 구성
5개 주제 영역의 Mart 구성
- 주제 영역1: 스마트카의 상태 모니터링 정보
- 주제 영역2: 스마트카의 운전자의 운행 기록 정보
- 주제 영역3: 이상 운전 패턴 스마트카 정보
- 주제 영역4: 긴급 점검이 필요한 스마트카 정보
- 주제 영역5: 운전자의 차량용품 구매 이력 정보
SmartCar 상태 정보 데이터 생성 100대
- CM > 플럼 > 시작
- Sever02 SSH 접속 시뮬레이터 위치로 이동
- cd /home/pilot-pjt/working
- java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.CarLogMain 20191117 100 &
- /home/pilot-pjt/working/SmartCar/SmartCarStatusInfo_20191117.txt
- ps -ef |grep smartcar.log
- kill -9 pid값
SmartCar 상태 정보 적재 - 플럼을 통해 수집
- cd /home/pilot-pjt/working/SmartCar/
- mv SmartCarStatusInfo_20191117.txt /home/pilot-pjt/working/car-batch-log/
- ls
- hdfs dfs -ls -R /pilot-pjt/collect/car-batch-log/
- .tmp 파일이 있으면 아직 적재 중
- 휴 파일브라우저에서 확인 가능
SmartCar 운전자 운행 로그 데이터 생성 100대
- CM > 플럼 , 카프카 > 시작
- Sever02 SSH 접속 시뮬레이터 위치로 이동
- service storm-nimbus start
- service storm-supervisor start
- service storm-ui start
- service redis_6379 start
- cd /home/pilot-pjt/working
- tail -f /home/pilot-pjt/working/driver-realtime-log/SmartCarDriverInfo.log
- java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.DriverLogMain 20191117 100 &
- redis-cli
- 127.0.0.1:6379> smembers 20191117
- 과속 차량 3대 이상 생성
- ps -ef |grep smartcar.log
- kill -9 pid값
주제 영역 1. 스마트카 상태 정보 모니터링 - 워크플로 작성
- 하이브 External => Managed 영역으로 매일 옮기기
- "스마트카 마스터 데이터"와 Join 통해 데이터 확장
- 작업 QL : CH06/HiveQL/2nd/
- CM > Oozie > 시작
- sudo -u hdfs hadoop fs -chown admin /pilot-pjt
- 휴 파일 브라우저 > /pilot-pjt/
- /workflow/hive_script/subject1~5 폴더 생성
- subject1폴더로 이동 > create_table_managed_smartcar_status_info.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.76.hql > 저장
- 기존 External영역의 smartcar_status_info, smartcar_master 칼럼으로 구성
- subject1폴더로 이동 > alter_partition_smartcar_status_info.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.77.hql > 저장
- 파티션 정보 추가
| alter table SmartCar_Status_Info add if not exists partition(wrk_date='${working_day}'); |
- working_day 값은 Oozie의 Coordinator 매개변수 today 할당 값을 가져옴
- subject1폴더로 이동 > insert_table_managed_smartcar_status_info.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.76.hql > 저장
- 동적 파티션 생성 시 하이브 환경 변수값 설정
|
set hive.exec.dynamic.partition=true; |
- SmartCar_Master_Over18 , SmartCar_Status_Info 테이블 조인
| SmartCar_Master_Over18 t1 join SmartCar_Status_Info t2 |
워크플로 만들기
- 휴 > 상단 메뉴 > Workflows > 편집기 > 워크플로 > 생성 > 선택
하이브 테이블 만들기
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject1/create_table_managed_smartcar_status_info.hql 선택 후 추가
SmartCar_Status_Info 테이블에서 오늘 날짜로 파티션 정보 설정 작업
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject1/alter_partition_smartcar_status_info.hql 선택 후 추가
- 매개변수 연결 : working_day=${today}
managed_smartcar_status_info 테이블에 데이터 저장 하기
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject1/ insert_table_managed_smartcar_status_info.hql 선택 후 추가
- 매개변수 연결 : working_day=${today}
My Workflow => Subject 1 - Workflow 변경 후 > 저장
작성한 워크플로 작동을 위한 Coodinator 생성
- 휴 > 상단 메뉴 > Workflows > 편집기 > Coodinator > 생성 > 선택
- Subject 1 - Coordinator 이름 변경
- 워크플로 선택 > Subject 1 - Workflow선택
간격 > 옵션 > 스케줄 작성
- 실행 간경: 매일, 01시
- 시작일자: 2019년 11월 18일, 00시 00분
- 종료일자: 2019년 12월 31일, 23시 59분
- 시간대: Asia/Seoul
- 매개변수 설정 : today / 매개변수 / ${coord:formatTime(coord:dateTzOffset(coord:nominalTime(),"Asia/Seoul"), 'yyyyMMdd')}
- 저장 > 제출
작성한 워크플로 작동을 위한 Coodinator 확인
- 휴 > 상단 메뉴 > Workflows > 대시보드> Coodinator > Running 확인
작성한 워크플로 바로 작동을 확인
- 휴 > 상단 메뉴 > Workflows > 대시보드> Coodinator > Running 확인
- 매개변수 설정 : today / 매개변수를 Hive smartcar_status_info 테이블 wrk_date 값으로 직접 입력 > 저장 > 제출
주제 영역 2. 스마트카 운전자 운행 기록 - 워크플로 작성
- Hive 로 smartcar_drive_info 조회
- select * from smartcar_drive_info order by date desc limit 10;
- 운전자 운행데이터(HBase) => 우지 워크플로워 => Managed Mart
- 운전자 운행데이터와 스마트카 마스터 데이터를 조인해서 확장된 운행 데이터 생성
- 작업 QL : CH06/HiveQL/2nd/
- 휴 파일브라우저 > /pilot-pjt/workflow/hive_script/subject2
HBase 테이터를 Hive로 재구성 할 테이블
- create_table_smartcar_drive_info_2.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.104.hql > 저장
- insert_table_smartcar_drive_info_2.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.105.hql > 저장
운행정보와 스마트카 마스터 데이터 조인 테이블
- create_table_managed_smartcar_drive_info.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.106.hql > 저장
- insert_table_managed_smartcar_drive_info.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.107.hql > 저장
워크플로 만들기
- 휴 > 상단 메뉴 > Workflows > 편집기 > 워크플로 > 생성 > 선택
하이브 테이블 만들기
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject2/create_table_smartcar_drive_info_2.hql 선택 후 추가
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject2/insert_table_smartcar_drive_info_2.hql 선택 후 추가
- 매개변수 연결 : working_day=${today}
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject2/create_table_managed_smartcar_drive_info.hql 선택 후 추가
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject2/insert_table_managed_smartcar_drive_info.hql 선택 후 추가
- 매개변수 연결 : working_day=${today}
My Workflow => Subject 2 - Workflow 변경 후 > 저장작성한 워크플로 작동을 위한 Coodinator 생성
- 휴 > 상단 메뉴 > Workflows > 편집기 > Coodinator > 생성 > 선택
- Subject 2 - Coordinator 이름 변경
- 워크플로 선택 > Subject 2 - Workflow선택
간격 > 옵션 > 스케줄 작성
- 실행 간경: 매일, 02시
- 시작일자: 2019년 11월 18일, 00시 00분
- 종료일자: 2019년 12월 31일, 23시 59분
- 시간대: Asia/Seoul
- 매개변수 설정 : today / 매개변수 / ${coord:formatTime(coord:dateTzOffset(coord:nominalTime(),"Asia/Seoul"), 'yyyyMMdd')}
- 저장 > 제출
작성한 워크플로 작동을 위한 Coodinator 확인
- 휴 > 상단 메뉴 > Workflows > 대시보드> Coodinator > Running 확인
작성한 워크플로 바로 작동을 확인
- 휴 > 상단 메뉴 > Workflows > 대시보드> Coodinator > Running 확인
- 매개변수 설정 : today / 매개변수를 Hive smartcar_drive_info 테이블 date 값으로 직접 입력 > 저장 > 제출
정리
- 매일 새벽 2시 스마트카 운전자 운행 데이터 => 하이브 테이블로 이전
- 다른 테이블과 조인을 통해 상세정보를 추가해 확장된 마트 데이터 생성
주제 영역 3. 이상 운전 패턴 스마트카 정보 - 워크플로 작성
- 스마트카 운전자의 운행 기록을 분석하여 과속, 급제동, 급회전이 빈번한 차량들을 스코어링한 마트 데이터 생성
- 과속과 급제동의 경우 당일의 차량별로 가속 페달과 브레이크 페달의 평균값 계산
- 관련 표준편차 값은 과거 모든 데이터를 대상으로 산출
- 과속/급제동 표준값이 각각 "2" 이상인 차량의 경우만 "비정상"으로 판단
- 급회전의 경우 당일 기준 Left/Right 회전각 "2~3" 단계를 "1000"번 이상인 경우 "비정상"으로 지정
- 작업 QL : CH06/HiveQL/2nd/
- 휴 파일브라우저 > /pilot-pjt/workflow/hive_script/subject3
스마트카 운전자들의 운행정보에서 이상 패턴 관리 테이블
- create_table_managed_smartcar_symptom_info.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.109.hql > 저장
- insert_table_managed_smartcar_symptom_info.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.110.hql > 저장
가속 패달
case
when (abs((t1.speed_p_avg_by_carnum - t3.speed_p_avg) / t4.speed_p_std)) > 2
then '비정상'
else '정상'
end
브레이크 패달
case
when (abs((t1.break_p_avg_by_carnum - t3.break_p_avg) / t4.break_p_std)) > 2
then '비정상'
else '정상'
end
운전대
case
when (t2.steer_a_count) > 1000
then '비정상'
else '정상'
end
- Job Browser 모니터링시 7개의 잡과 10개의 맵리듀스가 실행, 무거운 작업
워크플로 만들기
- 휴 > 상단 메뉴 > Workflows > 편집기 > 워크플로 > 생성 > 선택
하이브 테이블 만들기
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject3/create_table_managed_smartcar_symptom_info.hql 선택 후 추가
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject3/insert_table_managed_smartcar_symptom_info.hql 선택 후 추가
- 매개변수 연결 : working_day=${today}
My Workflow => Subject 3 - Workflow 변경 후 > 저장
작성한 워크플로 작동을 위한 Coodinator 생성
- 휴 > 상단 메뉴 > Workflows > 편집기 > Coodinator > 생성 > 선택
- Subject 3 - Coordinator 이름 변경
- 워크플로 선택 > Subject 3 - Workflow선택
간격 > 옵션 > 스케줄 작성
- 실행 간경: 매일, 03시
- 시작일자: 2019년 11월 18일, 00시 00분
- 종료일자: 2019년 12월 31일, 23시 59분
- 시간대: Asia/Seoul
- 매개변수 설정 : today / 매개변수 / ${coord:formatTime(coord:dateTzOffset(coord:nominalTime(),"Asia/Seoul"), 'yyyyMMdd')}
- 저장 > 제출
작성한 워크플로 작동을 위한 Coodinator 확인
- 휴 > 상단 메뉴 > Workflows > 대시보드> Coodinator > Running 확인
작성한 워크플로 바로 작동을 확인
- 휴 > 상단 메뉴 > Workflows > 대시보드> Coodinator > Running 확인
- 매개변수 설정 : today / 매개변수를 Hive smartcar_drive_info 테이블 date 값으로 직접 입력 > 저장 > 제출
- 그림2.112 하이브 쿼리 실행 결과 > 차트 실행
SELECT
car_number,
cast(speed_p_avg as int),
speed_p_symptom,
cast(break_p_avg as float),
break_p_symptom,
cast(steer_a_cnt as int),
steer_p_symptom,
biz_date
FROM managed_smartcar_symptom_info
where biz_date = '20191127'
과속/난폭 운전 가능성 예상 차량 찾기
- 차트 > 막대 , x축 car_number, y축 speed_p_avg
급정지/난폭 운전 가능성 예상 차량 찾기
- 차트 > 막대 , x축 car_number, y축 break_p_avg
운전대 비정상 패턴 차량 찾기
- 차트 > 막대 , x축 car_number, y축 steel_a_cnt
정리
- 하이브의 단순 기술 통계량으로 이상 징후 차량 탐색
- 하이브만 잘 활용해도 적재된 대량 데이터를 이용해 기술적 통계와 탐색적 분석석을 수행해 가치 있는 분석 가능
주제 영역 4. 긴급 점검이 필요한 스마트카 정보 - 워크플로 작성
- 타이어, 라이트, 브레이크, 엔진, 베터리 등을 분석
- 긴급 점검이 필요한 스마트카 차량 리스트 찾기
- "긴근 점검 차량" 마트를 만드는 시간은 많이 들지만 이후 빠르게 마트 조회
- 작업 QL : CH06/HiveQL/2nd/
- 휴 파일브라우저 > /pilot-pjt/workflow/hive_script/subject4
스마트카 장비의 상태를 관리하기 위한 테이블
- create_table_managed_smartcar_emergency_check_info.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.117.hql > 저장
- insert_table_managed_smartcar_emergency_check_info.hql 생성
- 파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.118.hql > 저장
타이어 점검
left outer join ( select
car_number,
avg(tire_fl) as tire_fl_avg ,
avg(tire_fr) as tire_fr_avg ,
avg(tire_bl) as tire_bl_avg ,
avg(tire_br) as tire_br_avg ,
'타이어 점검' as symptom
from managed_smartcar_status_info where biz_date ='${working_day}'
group by car_number
having tire_fl_avg < 80 or tire_fr_avg < 80 or tire_bl_avg < 80 or tire_br_avg < 80 ) t2
on t1.car_number = t2.car_number
라이트 점검
left outer join ( select
distinct car_number,
'라이트 점검' as symptom
from managed_smartcar_status_info
where biz_date = '${working_day}' and (light_fl = '2' or light_fr = '2' or light_bl = '2' or light_br = '2')) t3
on t1.car_number = t3.car_number
엔진 점검
left outer join ( select
distinct car_number,
'엔진 점검' as symptom
from managed_smartcar_status_info
where biz_date = '${working_day}' and engine = 'C' ) t4
on t1.car_number = t4.car_number
브레이크 점검
left outer join ( select
distinct car_number,
'브레이크 점검' as symptom
from managed_smartcar_status_info
where biz_date = '${working_day}' and break = 'C' ) t5
on t1.car_number = t5.car_number
배터리 점검
left outer join (select
car_number,
avg(battery) as battery_avg,
'배터리 점검' as symptom
from managed_smartcar_status_info where biz_date = '${working_day}'
group by car_number having battery_avg < 30 ) t6
on t1.car_number = t6.car_number
피처(특징) 엔지니어링 P284 Tip 확인
- 데이터셋 확인 => 결측값 처리 => 이상값 처리 => 피처 엔지니어링
- 주요 필드 등을 가공해 새로운 변수를 만들어 내는 것
워크플로 만들기
- 휴 > 상단 메뉴 > Workflows > 편집기 > 워크플로 > 생성 > 선택
하이브 테이블 만들기
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject4/create_table_managed_smartcar_emergency_check_info.hql 선택 후 추가
- HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject4/insert_table_managed_smartcar_emergency_check_info.hql 선택 후 추가
- 매개변수 연결 : working_day=${today}
My Workflow => Subject 4 - Workflow 변경 후 > 저장
작성한 워크플로 작동을 위한 Coodinator 생성
- 휴 > 상단 메뉴 > Workflows > 편집기 > Coodinator > 생성 > 선택
- Subject 4 - Coordinator 이름 변경
- 워크플로 선택 > Subject 4 - Workflow선택
간격 > 옵션 > 스케줄 작성
- 실행 간경: 매일, 04시
- 시작일자: 2019년 11월 18일, 00시 00분
- 종료일자: 2019년 12월 31일, 23시 59분
- 시간대: Asia/Seoul
- 매개변수 설정 : today / 매개변수 / ${coord:formatTime(coord:dateTzOffset(coord:nominalTime(),"Asia/Seoul"), 'yyyyMMdd')}
- 저장 > 제출
작성한 워크플로 작동을 위한 Coodinator 확인
- 휴 > 상단 메뉴 > Workflows > 대시보드> Coodinator > Running 확인
작성한 워크플로 바로 작동을 확인
- 휴 > 상단 메뉴 > Workflows > 대시보드> Coodinator > Running 확인
- 매개변수 설정 : today / 매개변수를 Hive smartcar_drive_info 테이블 date 값으로 직접 입력 > 저장 > 제출
정리
- 긴급 점검 대상 차량을 판단하는 것은 주관적
- 과거의 긴급 점검이 실제 이뤄진 차량의 이력 정보과 지속적인 데이터 탐색을 한다면 신뢰도 상승
- 빅데이터는 저장 공간과 컴퓨팅 파워에 대한 제약이 적으므로 과거 데이터를 최대한 많이 적재해 분석 정확도 향상 가능
주제 영역 5. 스마트카 운전자 차량 용품 구매 이력 정보 - 워크플로 작성
- 스마트카 차량용품 구매 이력과 스마트카 마스터 데이터를 결합한 데이터셋 생성
- SmartCar_Master_Over18 join SmartCar_Item_Buylist
- 동적 파티션은 월단위로 생성
- 차량번호별 구매한 상품 리스트를 로컬 파일시스템에 생성
- 작업 QL : CH06/HiveQL/2nd/
- 휴 파일브라우저 > /pilot-pjt/workflow/hive_script/subject5
스마트카 차량용품 구매 이력과 스마트카 마스터 데이터 조인 테이블
-
create_table_managed_smartcar_item_buylist.hql 생성
-
파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.120.hql > 저장
-
insert_table_managed_smartcar_item_buylist.hql 생성
-
파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.121.hql > 저장
차량별 상품 구매 리스트 결과 파일 생성 스크립트
-
local_save_managed_smartcar_item_buylist.hql 생성
-
파일 클리 > 우측 메뉴 > 파일 편집 > 그림-6.122.hql > 저장
-
collect_set() 함수를 이용해 차량번호별로 그루핑한 결과를 하나의 상품리트로 재구성
워크플로 만들기
- 휴 > 상단 메뉴 > Workflows > 편집기 > 워크플로 > 생성 > 선택
하이브 테이블 만들기
-
HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject5/create_table_managed_smartcar_item_buylist.hql 선택 후 추가
-
HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject5/insert_table_managed_smartcar_item_buylist.hql 선택 후 추가
-
HiveSever2 스크립트 추가 > /pilot-pjt/workflow/hive_script/subject5/local_save_managed_smartcar_item_buylist.hql 선택 후 추가
My Workflow => Subject 5 - Workflow 변경 후 > 저장
작성한 워크플로 작동을 위한 Coodinator 생성
- 휴 > 상단 메뉴 > Workflows > 편집기 > Coodinator > 생성 > 선택
- Subject 5 - Coordinator 이름 변경
- 워크플로 선택 > Subject 5 - Workflow선택
간격 > 옵션 > 스케줄 작성
- 실행 간경: 매일, 05시
- 시작일자: 2019년 11월 18일, 00시 00분
- 종료일자: 2019년 12월 31일, 23시 59분
- 시간대: Asia/Seoul
- 저장 > 제출
작성한 워크플로 작동을 위한 Coodinator 확인
- 휴 > 상단 메뉴 > Workflows > 대시보드> Coodinator > Running 확인
작성한 워크플로 바로 작동을 확인
- 편집 워크플로에서 바로 제출
- 데이터 생성 확인
|
select * from managed_smartcar_item_buylist_info |
- 차량 번호별로 그루핑된 상품 리스트 파일 생성 확인
- more /home/pilot-pjt/item-buy-list/00000_0
'BigData' 카테고리의 다른 글
| 빅데이터 적재 - 실시간 로그 파일 적재 (0) | 2020.06.29 |
|---|---|
| Bigdata - 빅데이터 적재-대용량로그 (0) | 2020.06.22 |
| 리눅스 기본 명령어 (0) | 2020.06.17 |

댓글